
【MIT6.172】学习笔记(1)

前言
本文为MIT6.172的笔记,每篇文章最后对该篇文章的内容会做一简要总结。
本系列假设读者对计算机组成原理,操作系统已经有清晰的认识。
注意,这篇博客更倾向于作者的个人笔记,质量不太高,并且可能有事实上的错误(尽量避免)。如果发现,请随意批评指出。
Lecture 1 初步介绍&矩阵乘法
软件设计:有哪些数学更重要?兼容性,正确性,清晰,可debug,模块化,移植性,可维护性,功能性,可靠性,健壮性,可测试性,可用性。
那么性能是什么?性能是用于“兑换”以上性质的“通货”。
功耗墙:限制了cpu频率的进一步增长。后来转向多核设计。多核设计引入了更复杂的存储器体系结构(Shared memory, Distributed memory)
摩尔定律:每过半年,晶体管的数目就要翻一番。(为什么近代开始失效?)
以矩阵乘法为例:哪些因素会影响代码的执行?如何优化?
①常规的矩阵乘法,速度为:Python<Java<C:
- Python为解释执行的语言
- 解释器:灵活但速度缓慢,支持动态代码修改。工作原理为:读取一行代码,解释,执行,更新状态,如此循环
- Java先由编译为字节码(平台架构无关),再由解释器解释为对应平台的机器码
- 即时编译(JIT compilation):会将部分高频执行的字节码保存为机器码,加速执行,恢复因为解释而丢失的性能。
- C则是直接解释为对应的机器码
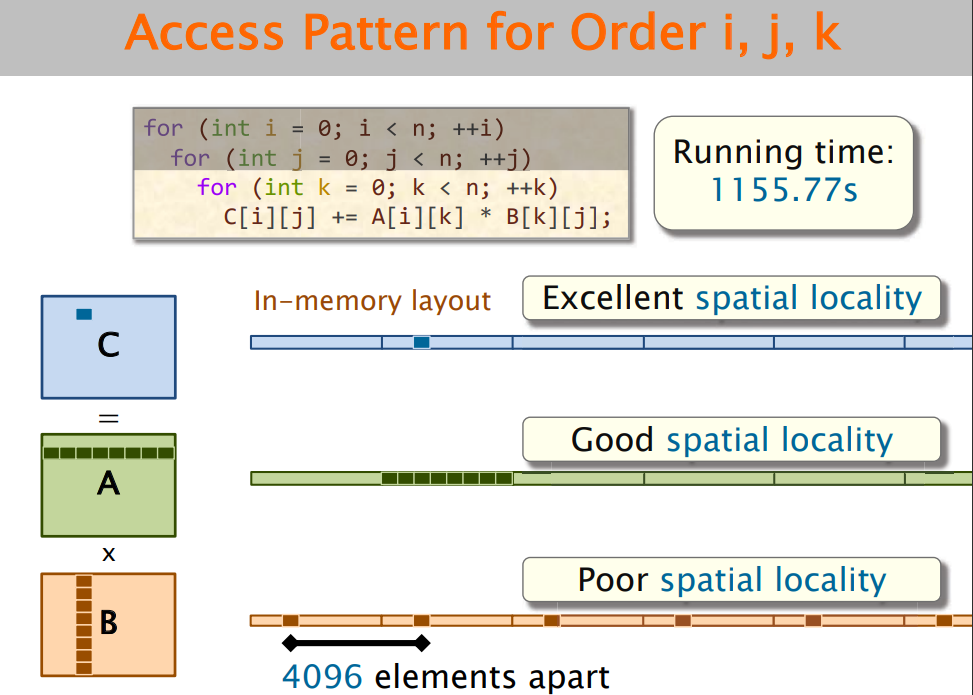
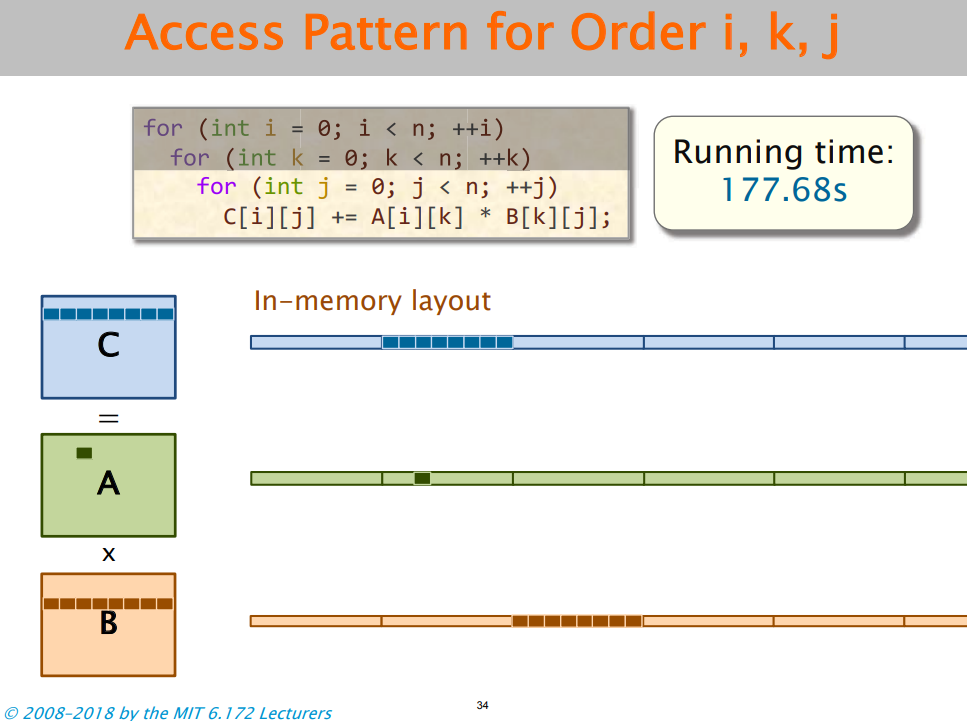
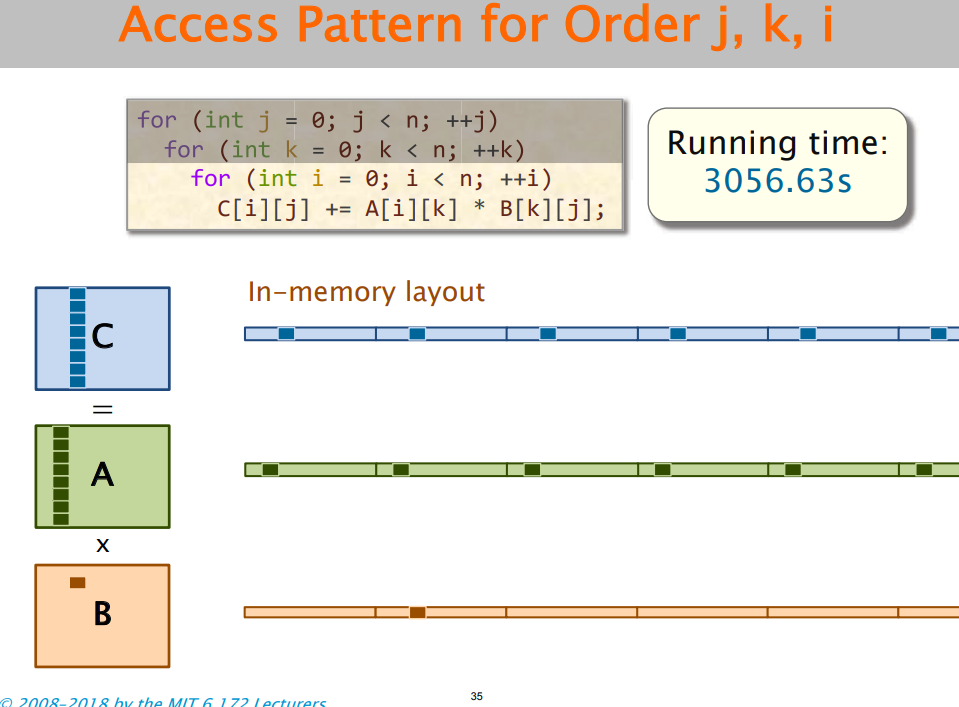
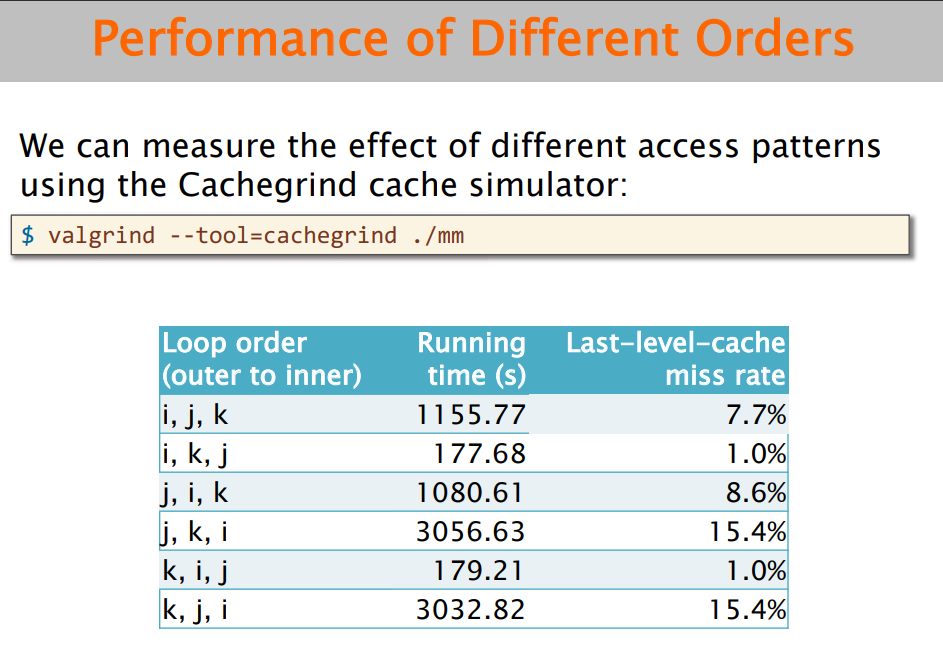
② 缓存缺失:i,j,k的不同顺序会有影响,原因不再赘述。需要关注数据结构在内存中的排布。
③编译优化
针对C:-O0到-O3的优化程度越来越高(但实际性能则不一定),另外-Os是优化程序空间大小,-Og是为了debug。
④并行化循环
利用多核心,对循环进行并行化。记住,优先并行化外层循环,因为并行化操作本身也需要开销,并行化操作次数越少越好。(但不是所有代码都易于并行化)
⑤块划分
采用合适的划分方式,使得每块的访存次数尽量少:
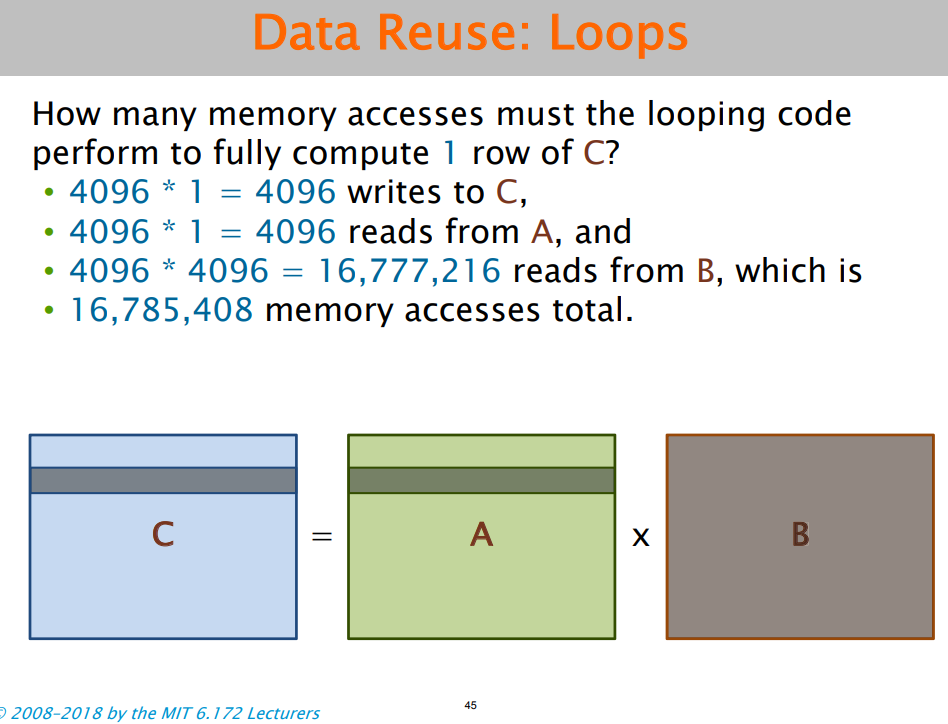
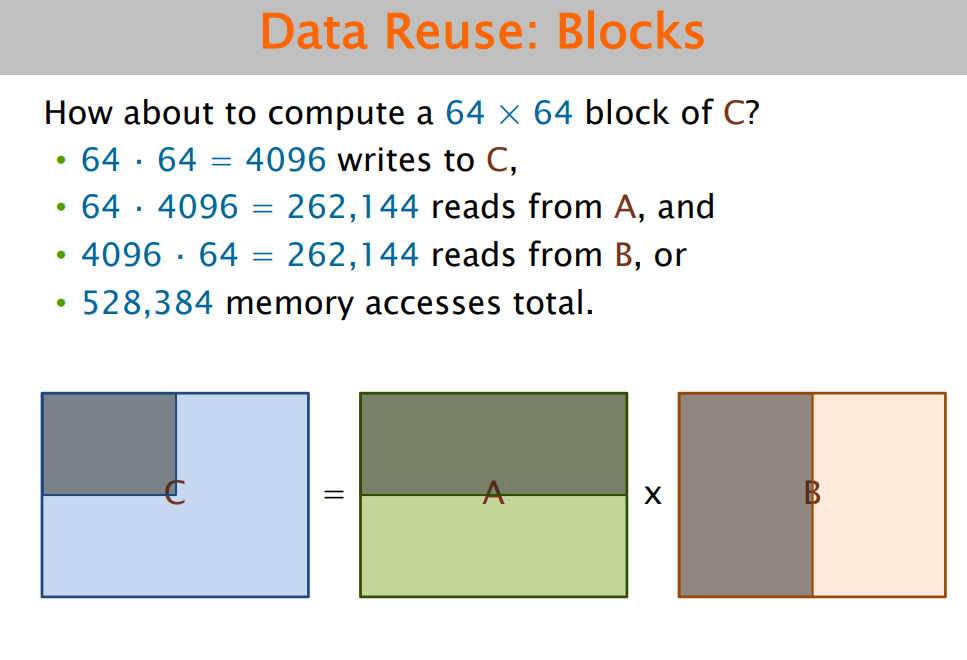

如图,每个核心负责算矩阵乘法某一小方块的内容即可。至于块大小如何划分,需要做实验才能知道。(每个核心负责算一块的内容)。在代码中,ih和jh相当于把一小块的base定下来了,k也相当于定了个base。
⑥基于两级Cache的划分
下图是现代处理器的常见架构。
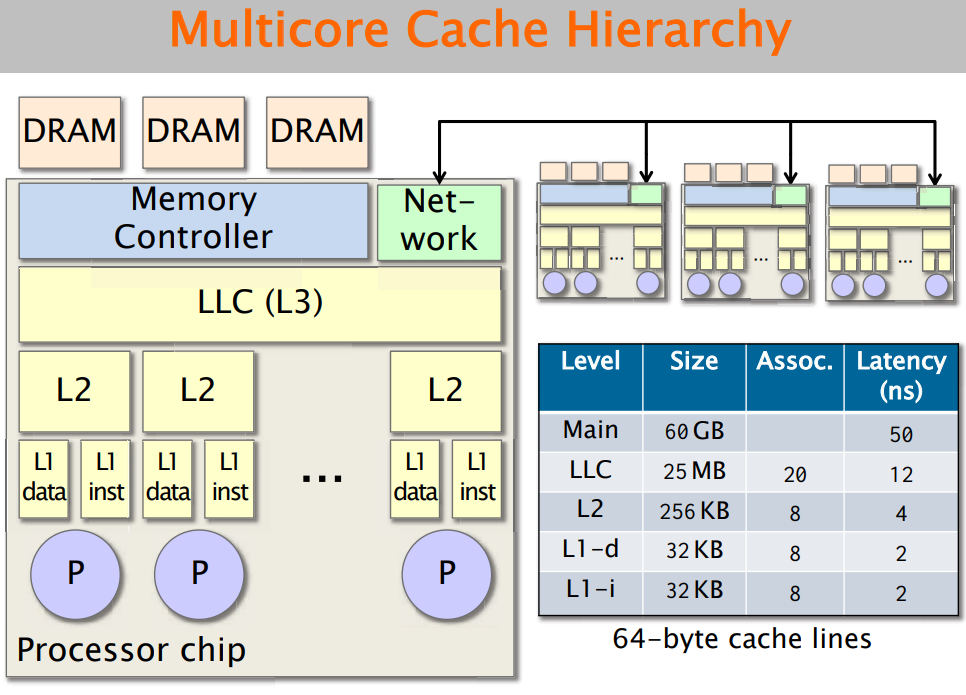
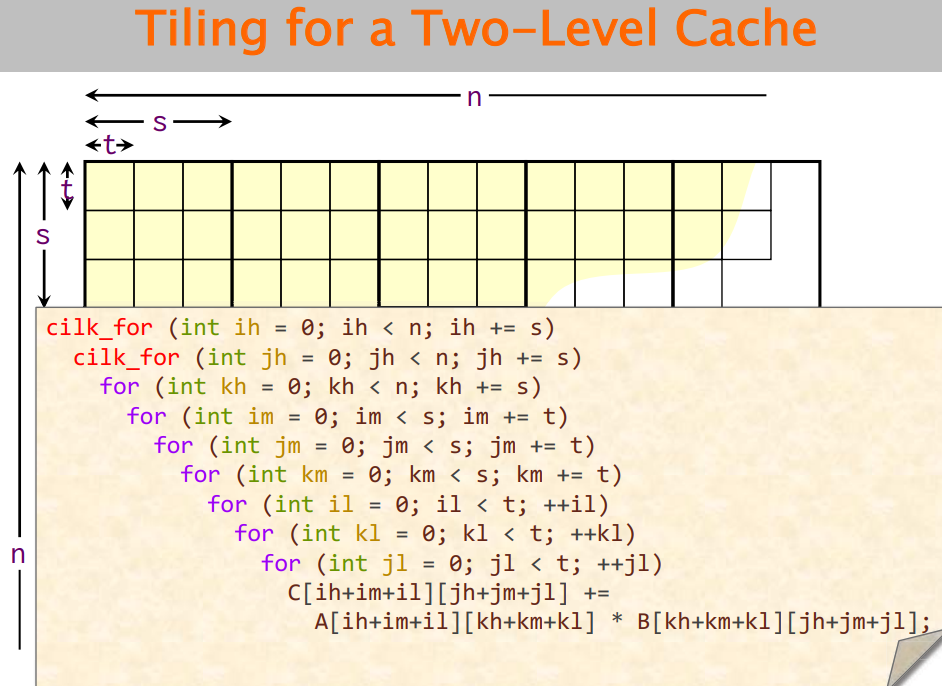
需要测试的参数包括s和t。
⑦分治
idea:矩阵乘法可以分解为更小的矩阵乘法(分块矩阵)
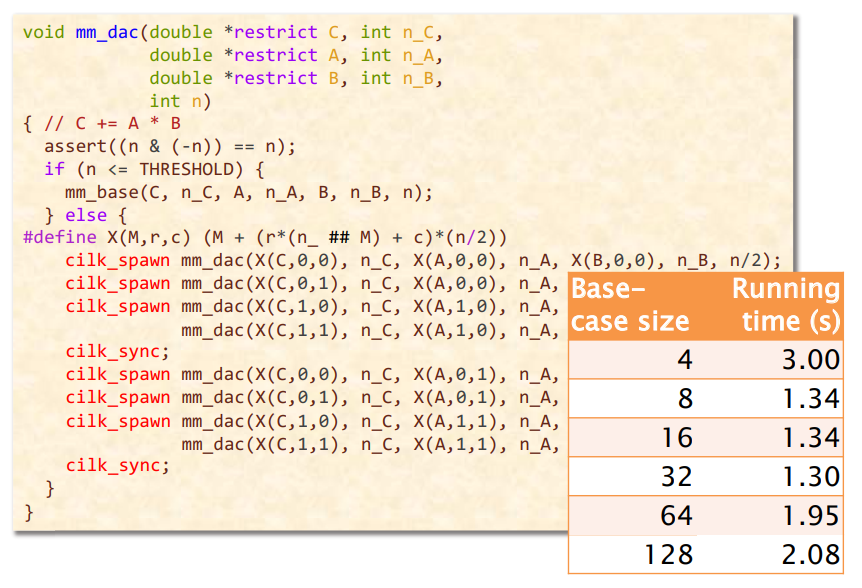
需要强调的是这个矩阵是个方阵,如果需要支持其它矩阵,则需要进行修改。如果n不是2的幂,还需要仔细考虑边界问题(这个程序的assert就是用于判断是不是2的幂)。(作者的想法是,考虑满足r,c为2的幂的矩阵乘法的写法,然后把所有矩阵递归地分解为这样的矩阵。。。)
其中:
- cilk_spawn表示并行化进行,cilk_sync表示同步,注意THRESHOLD判断条件。
- 再注意mm_dac函数的入参:是原矩阵的大小,但n代表当前矩阵的大小。
- 再注意那个宏展开:r是分块矩阵的行,c是分块矩阵的列,宏展开的结果是指针的偏移量,其实是子矩阵的base。详细地说,一个“单位”的大小为n/2,
(r * (n_[A-C])) + c代表有多少个这样的单位。这样就好理解了。 - 再回到mm_base函数,为什么要传入n_C,n_A,n_B,是为了方便计算偏移量。
1
2
3
4
5
6
7
8C[i][j] -> C[i * n_C + j]
这个该如何理解呢?这是需要联系内存排布的:
|--|--|
| | |
|--|--|
| |√ |
|--|--|
考虑右下角的分块矩阵,我们有指针指向这块矩阵的第一个元素,那么该如何索引到这块矩阵的下一行元素的第一个元素呢?答案就是上式的转化。
⑧编译器向量化优化
需要开启-O2以上的优化。显示指定包括:
-mavx:启用avx-mavx2:启用avx2mfma:启动乘法-加法向量指令-march=<string>:使用指定架构上的任何指令-march=native:使用本机架构的所有指令
另外需要提到的是,使用某台架构的机器编译另外一种架构的编译行为叫做交叉编译。
⑨手动向量化优化(内置向量化)
使用内置函数。
⑩baseline:Intel MKL(Math Kernel Library )
Lecture 2 Bentley工作量优化准则
工作量:对于给定输入,一个程序所执行的所有操作,
优化工作的角度:算法(很明显),利用计算机硬件的特性:ILP,cache,向量化,预测和分支预测,等等。
- 数据结构
- 打包和编码:将一些信息编码,使用更少的bit位进行表示。经典例子如一个int保存了32个flag,缺点是需要解码,增加编码困难。
- 数据增广:使用额外的数据保存额外的信息,比如单向链表,可以保存尾指针,实现插入的常数时间插入。
- 预计算:俗称打表
- 编译期优化:还是打表
- 缓存:将计算过的结果保存起来,以便于下一次用到。典型应用是记忆化搜索。
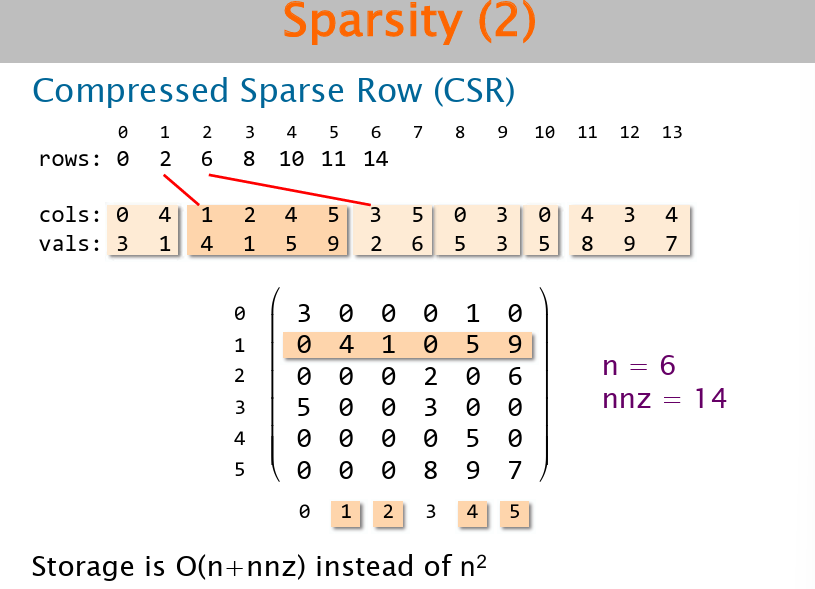
- 稀疏性:某些数据结构,有大量无用数据,如稀疏矩阵,此时可以考虑用其它数据结构保存稀疏矩阵,以减少空间。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16typedef struct{
int n, nnz;
int * rows;
int * cols;
double* vals;
} spm;
// 矩阵乘以向量。。。
void spmv(spm *A, double* x, double* y){
for (in i = 0; i < A->n; i++){
y[i] = 0;
for (int k = A->rows[i]; k < A->rows[i+1]; k++){
int j = A->cols[k];
y[i] += A->vals[k] * x[j];
}
}
}
- 代码逻辑
- 常数折叠与传播:写过编译器的都知道这个方法,如果变量是常数,后面的表达式也是常数变量的话,那么编译期就可以算出这个结果。
- 共同表达式消除:
b = a - c, d = a - c => b - a - c, d = b - 代数恒等式:开方的开销是比平方大的,那么不妨把开方化成平方?
- 短路运算:如果在循环中间已知结果,那么可以提早退出。
- 条件排序:将最可能能得出整个表达式结果的条件排到前面
- 创建快速路径:一个函数首先算出一些平凡常见的状况,避免开销更大的判断方法
- 混合测试条件:其实就是用真值表,结合switch-case语句进行使用
- 循环
- 循环无关代码外提:不依赖于循环变量的语句全部扔到循环外面去
- 哨兵值:如果循环内有判断语句,不妨考虑在数据结构里面嵌入哨兵值,减少判断语句的使用。
- 循环展开:分为循环全展开和循环部分展开
- 循环聚合:将循环范围相同的循环结合在一起
- 消除多余的迭代:
- 函数
- 函数内联:减少函数调用开销
- 尾递归:将递归语句放到return(最后)的位置,那么编译器会做优化,直接覆盖当前栈帧,而不是新开一个栈帧。
- 粗粒度递归:当问题规模减小到一定程度时,如果继续递归下去,调用开销大于解决这个问题的开销时,就转为直接解决这个问题,而不是继续递归。
- 其它建议
- 避免过早的优化,先写正确的代码,保证正确性,使用回归测试
- 编译器帮你干了以上很多工作,但是是否启用了,还是要查看编译器代码。
- TODO:介绍cpp的restrict和volatile关键字。。。


Lecture 3: bit hacks
这一章就介绍了各种奇奇怪怪的bit operation,目的是:在编译器不自动优化时,自己手动优化(但绝大多数情况下编译器比你优化的好)。这里记录一下有意思的。
无中间变量的交换
1
2
3x = x ^ y;
y = x ^ y;
x = x ^ y;
但是不利于挖掘ILP寻找较小值
r = y ^( (x ^ y) & -(x < y) );

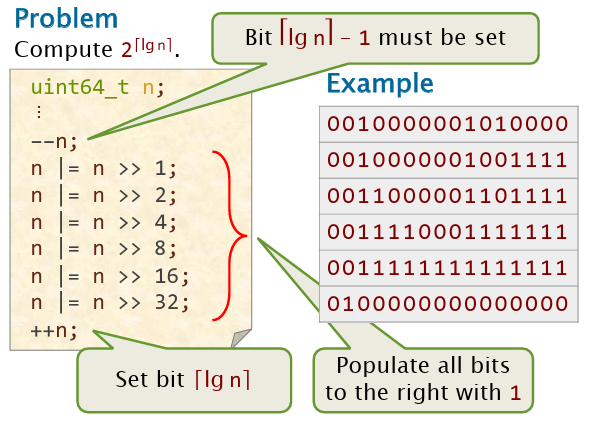
lowbit操作
r = x & (-x)八皇后问题
记录状态可以用bit位操作,而不需要数组获取一个数的二进制的1的数量
1
2for(r = 0; x!=0; r++)
x &= x - 1
1
2
3
4static const int count[256] =
{0, 1, 1, 2, 1, ..., 8}
for (int r = 0; x != 0; x >>= 8)
r += count[x & 0xff]

还可以使用编译器内置函数(但移植性可能很差!)
int __builtin_popcount (unsigned int x)
Lecture 4: 汇编语言和计算机体系结构
编译的四个步骤:
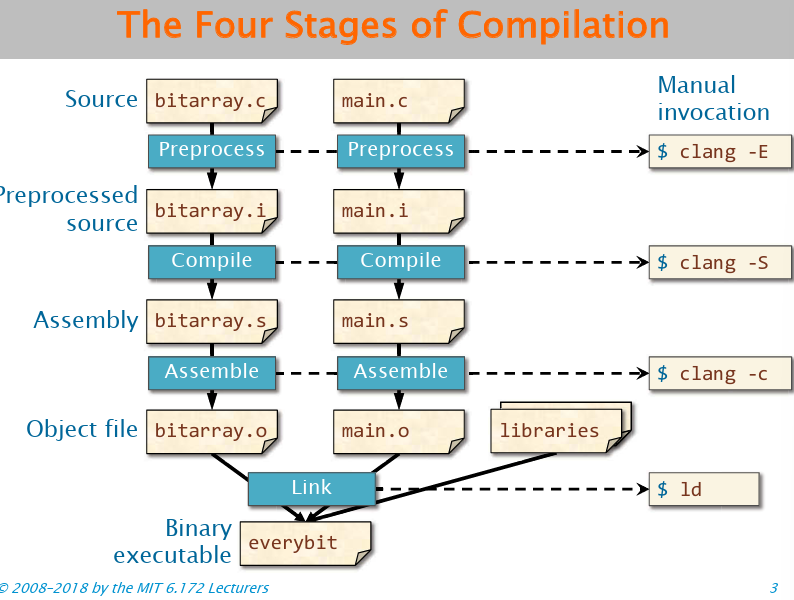
反汇编:objdump -S fib(前提是编译的时候带了-g选项)
ISA:定义了语法和语义。包括:寄存器,指令,数据类型,访存模式。
x86-64指令集
x86-64寄存器介绍
x86-64有如下寄存器:
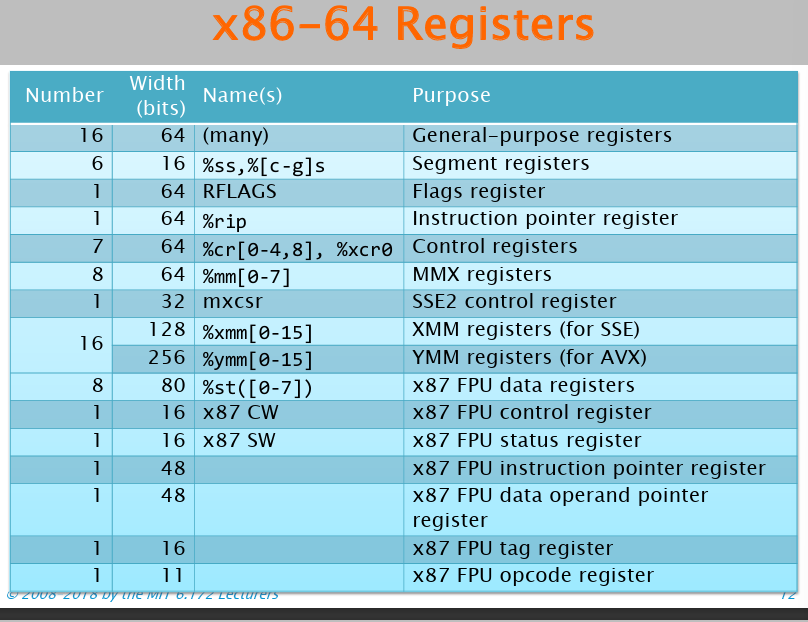
其中通用寄存器,根据所使用的位宽不同,同一个寄存器有不同名字:一个寄存器根据使用的byte不同可能有多个名称,主要改动为寄存器前缀,但八位会改变后缀。[e**, r**, **, *h/*l],

部分寄存器可能采用其它名称,改变的是后缀。[**d, **w, **b]
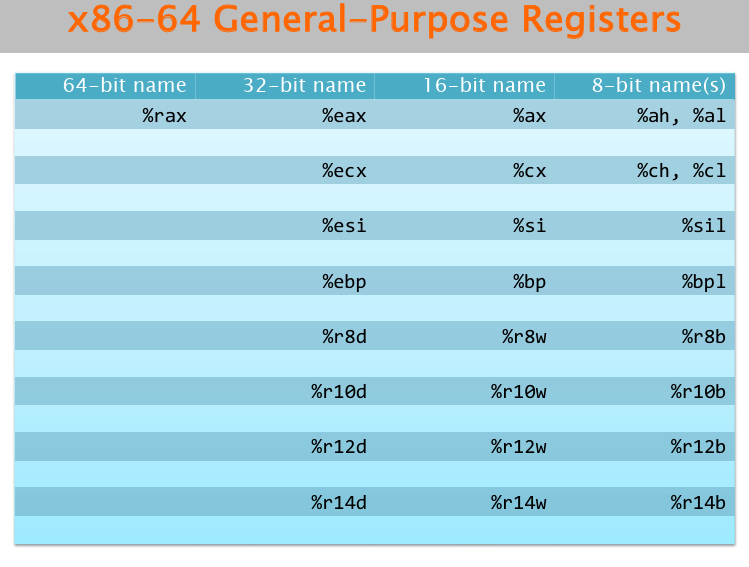
这些后缀的含义见下一节。
x86-64指令介绍
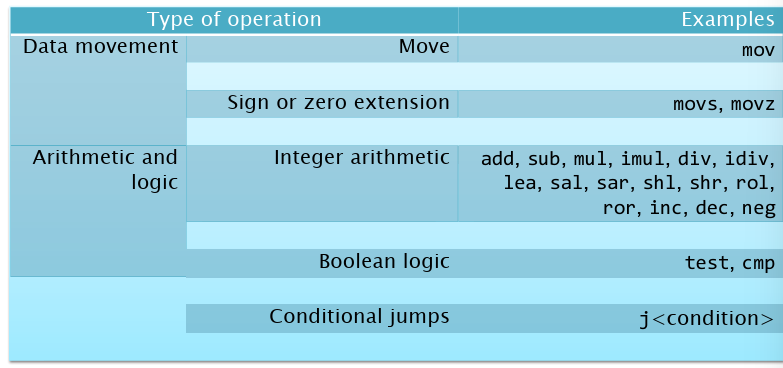
x86-64的指令,大致可以分为:数据移动,算数和位运算,以及跳转指令。其中指令后缀暗示数据类型。如subq表示64位整数。如果没有后缀,则会从操作数推断。
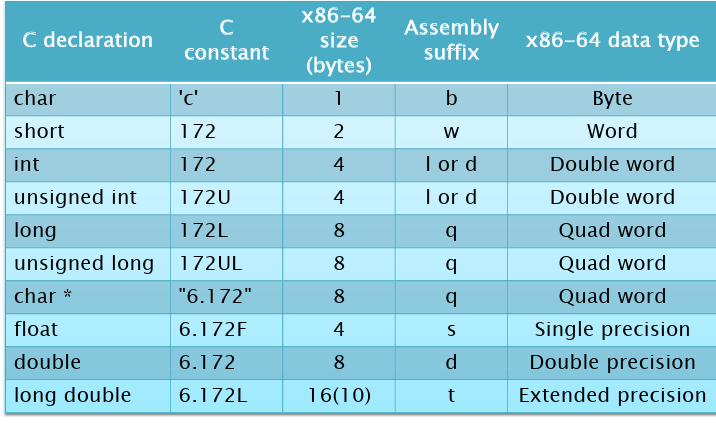
下面是数据类型对应的后缀,可以稍微归纳一下,浮点数比较特殊:依次为s,d(ouble),t。其他的数据类型为b(yte), w(ord), l(ong)/d(ouble), q(毕竟本质都是整数)。特殊一点的是d,在浮点数和整数都出现过。
下面是一些特殊指令的介绍:
关于
mov指令,有两种需要关注的后缀:标识扩展方式的后缀和标识数据位宽的后缀。如movzbl的z表示零扩展,bl表示从8bit移动到32bit;movslq的s表示符号扩展,lq表示从32bit移动到64bit。需要注意一个问题:32位扩展到64位采用的是隐式零扩展,和8位和16位的结果不同(是什么?待补)。
关于
j指令:通常按照RFLAGS保存d的内容来判断s是否跳转,而RFLAGS的值由cmp显式改变(其他指令的执行结果也会改变RFLAGS寄存器的值)。RFLAGS的内容如下:在正常情况下,只需要关注RFLAGS的四个域:CF,ZF,SF和OF。其中:- CF表示上一个ALU运算是否进位
- ZF表示上一个运算结果是否是0
- SF表示上一个运算结果的正负值,正0负1
- OF表示上一个运算结果是否溢出。
对于
j的判断条件后缀,如下表所示。如ja,jae等等。另外,思考一下ge的判断条件为什么是SF=OF?考虑不溢出的情况,那么ge意味着所算出的结果一定是正数,那么SF=OF=0;考虑溢出的情况(INT_MAX-INT_MIN),那么算出来的结果本身为正数,但是因为溢出变成了负数,那么SF=OF=1,也成立;(INT_MIN-INT_MAX),那么结果为负数,下溢变成正数,那么SF=0, OF=1,也成立。最后注意
j的操作数,可以是label,也可以是直接地址,也可以是间接地址:
1
2
3jmp .L1
jmp 5
jmp *%eax
### x86指令的寻址模式直接访存模式(Direct Addressing Mode)
- 立即数:使用声明的立即数:
movq $172, %rdi - 寄存器:使用指定存储器存储的数据:
movq %rcx, %rdi - 内存访问:使用常数指定内存地址,使用对应内存地址所存储的数据,
movq 0x172, %rdi
- 立即数:使用声明的立即数:
间接访存模式(Indirect Addressing Mode)
- 寄存器间接寻址(Register indirect):使用寄存器所存的值作为内存地址:
movq (%rax), %rdi - 寄存器基址寻址(Register indexed):使用寄存器所存的值作为基地址,加上offset进行访存:
movq 172(%rax), %rdi - 指令计数器相对寻址(Instruction-pointer relative):使用
%rip(类似于MIPS的PC,只不过x86是CISC
CISC,指令是变长的,所以估计没有程序计数器这个概念)的值作为基地址。movq 172(%rip), %rdi - 基地址放缩位移寻址(Base Indexed Scale Displacement)
需要注意的是地址的计算方式,以及两个寄存器是通用寄存器(GPR)。第一个GPR存base,第二个GPRc存Index。以及scale默认是1,可取1,2,4,8。
- 寄存器间接寻址(Register indirect):使用寄存器所存的值作为内存地址:
 在正常情况下,只需要关注RFLAGS的四个域:CF,ZF,SF和OF。其中:
在正常情况下,只需要关注RFLAGS的四个域:CF,ZF,SF和OF。其中: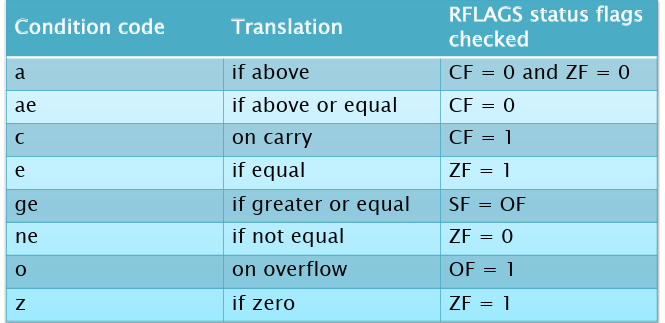 如
如
tricks
1 | # 1 |
浮点数与向量体系结构
浮点数指令集
x86支持float和double,x87加入了long double。SSE和AVX指令也包括了向量指令。编译器更喜欢使用SSE,因为SSE更容易编译和优化。对于SSE指令,使用两个字母的后缀来标识数据类型:[sp][sd]

例:
1 | movsd (%rcx,%rsi,8), %xmm1 |
向量体系结构
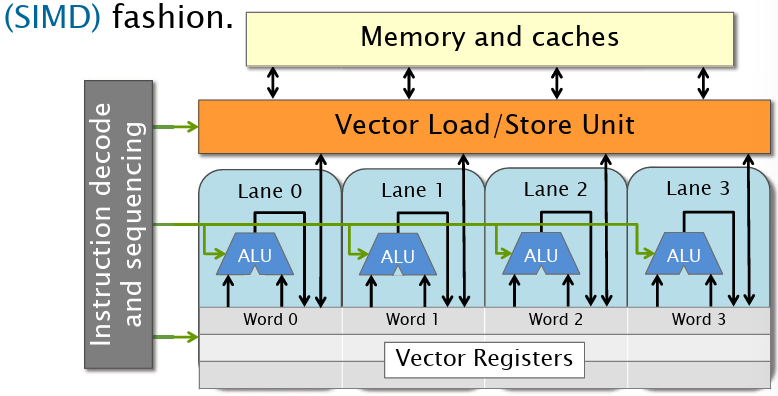
令k为向量位宽,每个向量寄存器保存k个整数或者浮点数。每个单元拥有k个向量车道,每个车道包含标量计算单元。每个车道使用相同的指令(也就是SIMD的体现了)。
对于向量体系结构,有以下特点:
- 内存排布可能需要对齐
- 向量寄存器只能“按位操作”,即一个向量寄存器的第i个元素只能和另外一个向量寄存器的第i个元素进行操作
- 某些体系结构支持车道交叉(cross-lane)操作,如插入或提取一个向量的子集,洗牌,分散和集中操作。
下面是x86-64支持的标准:
- SSE:整数,单精度浮点数和双精度浮点数向量操作
- AVX:单精度浮点数和双精度浮点数向量操作
- AVX2:加入了整数向量操作
- AVX3(AVX-512):扩大向量寄存器宽度到512,加入了新操作(如popcount,为1的个数)
SSE和AVX*的比较:
- SSE使用xmm寄存器,长度为128bit,最多同时操作两个操作数
- AVX使用ymm寄存器,长度为256bit,最多接受三个操作数:
vaddpd %ymm0, %ymm1, %ymm2,其中%ymm2为目标寄存器。
最后,前缀也有两个进行表示:[v ][p ],其中第一个前缀,带v则用avx,否则是sse;第二个前缀,带p则是整数,否则为浮点数。(别忘了前面的后缀)
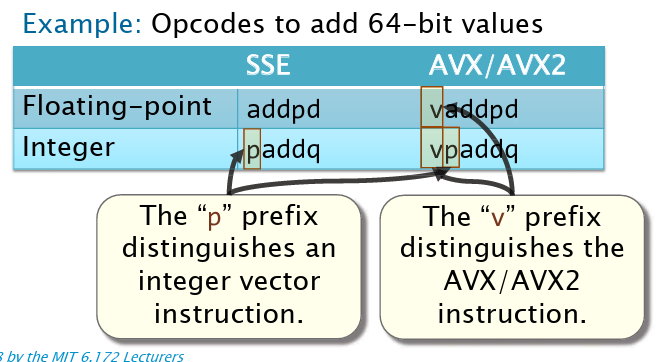
另外,向量寄存器也有类似于通用寄存器的别名:ymm的低128位为xmm,ymm总共有256位。
计算机体系结构:概述
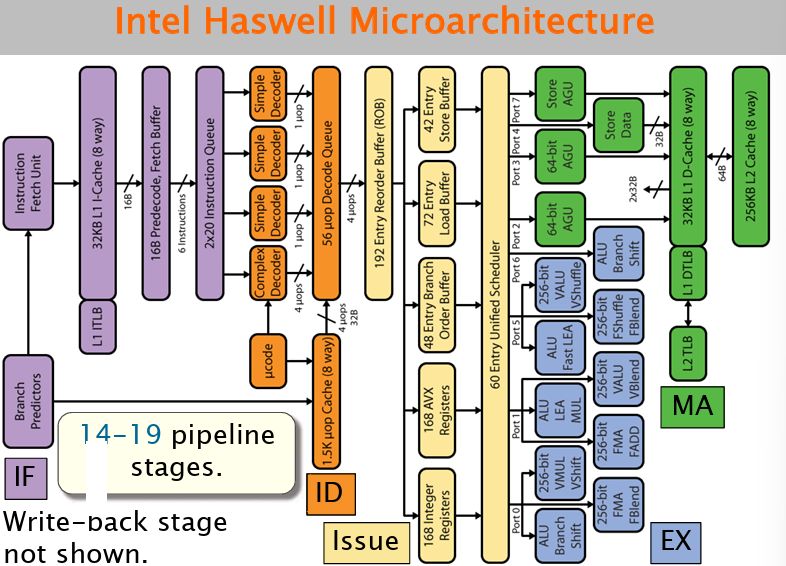
首先介绍了经典五级流水线,这个应该都熟悉,下面看看Intel Haswell Microarchitecture的架构,大概有14-19级的流水线,先看看了解一下。
从计算机体系结构上进行提升,主要有两种手段:
- 开发ILP:如向量化,指令级并行,多核操作
- 利用局部性原理:如使用cache
超标量处理(实现多发射)
使用流水线,但是需要关注三种数据依赖类型:真依赖(RAW),反依赖(WAR)和输出依赖(WAW)。但由于部分操作时延较长,增加了流水线的设计复杂度,如下图所示。
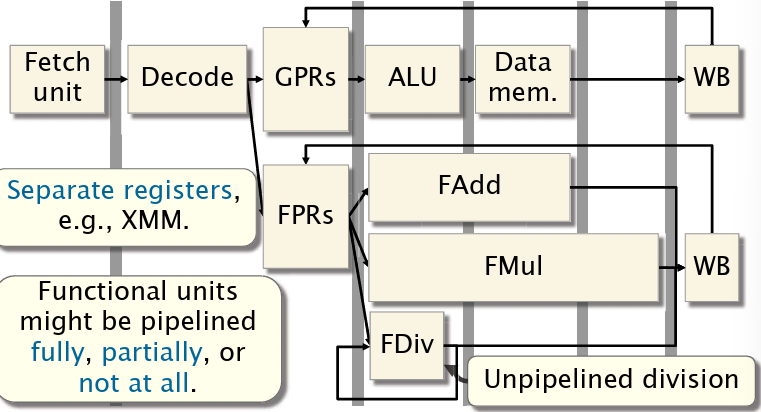
下图是Intel Haswell的功能单元设计:
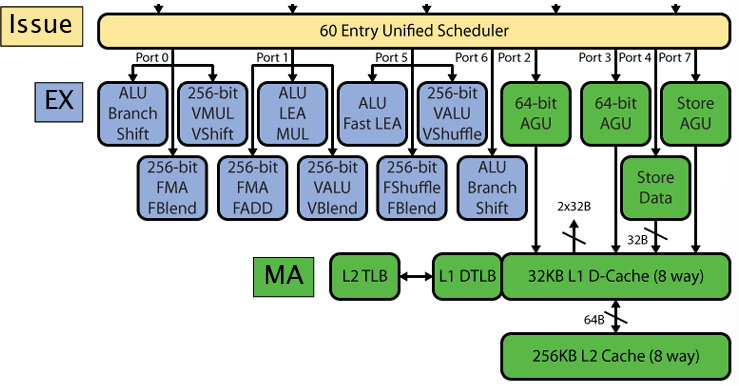
从流水线如何过渡到超标量?答案是进行多发射,保证每个功能单元都在执行任务(理想状况!)这里展示Intel Haswell的取指和解码阶段的架构:
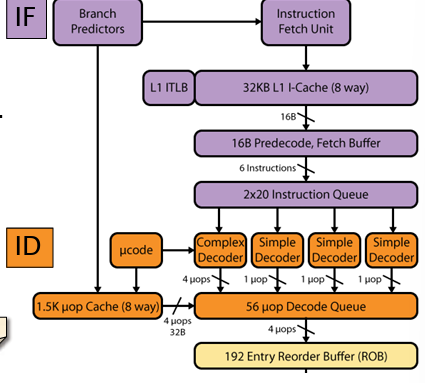
其采用了微指令体系结构,作用是将一条复杂指令分解为更多简单的指令。其包括一个复杂指令的解码器,每周期发射四条微指令。
乱序执行
流水线中一个重要的问题是数据依赖问题,对于RAW来说,常见的方案是数据前推(By passing)。对于一个指令流,我们可以建立一个指令依赖图。如下图所示
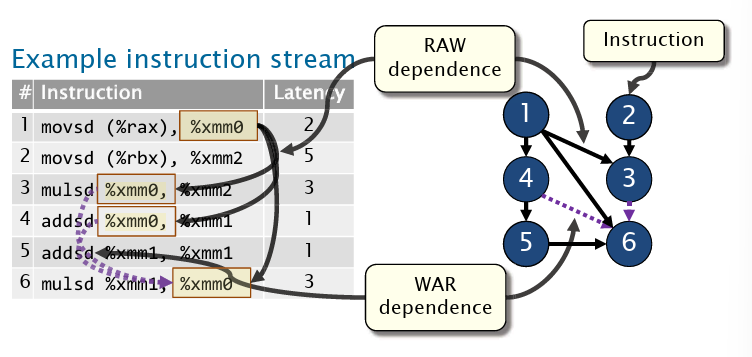
而对于顺序发射,WAR和WAW似乎都不是问题,但如果是乱序执行呢?可以使用寄存器重命名技术!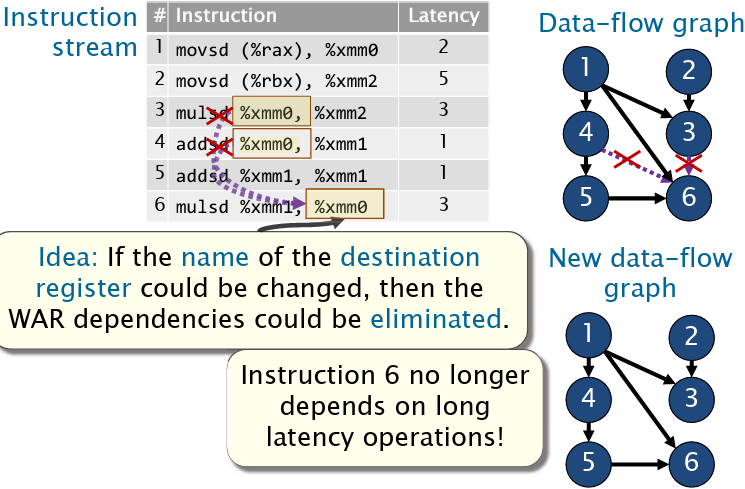
那么,乱序执行下,WAR和WAW可以通过重命名技术解决,而RAW造成的性能损失,在乱序发射的场景下,性能损失得到减少。下面将具体研究动态寄存器重命名技术。
在体系结构中,会使用更多的寄存器保存因为WAR和WAW而多出来的值。维护这个关系的表叫做重命名表(renaming table),其中维护ISA规定的寄存器号到物理寄存器号的映射。而物理寄存器由Freelist进行维护。
关于寄存器重命名及动态排序的算法,推荐直接查找ppt看,图示较多,这里用我的语言介绍一下算法步骤:

上图为重排序缓冲(reorder buffer, ROB),用于跟踪指令间的依赖关系。每个指令拥有tag。source,dest以及重命名表的Data域可能取tag,也可能取物理寄存器。下面分两种情况讨论:
- 当一个新的指令进入buffer时,首先检查source,根据重命名表判断是否来自未执行完的指令,并在ROB记录对应的tag,然后检查Dest,在重命名表中更新对应寄存器的tag。
- 当一个指令执行完毕后,从ROB删除该项,并在重命名表中更新Data,如果tag和该指令的tag相同,则更新到对应的物理寄存器,并将ROB的对应Source项也进行更改(从tag改到物理寄存器)。
总之,在乱序执行场景下,数据依赖关系可以通过图进行建模,而且只有RAW会影响性能,WAW和WAR几乎不影响性能。
分支预测
这一小节重点考虑控制冒险的问题。
在IF阶段就需要知道分支判断的结果,但是需要在EXE阶段才能计算得到结果。因此有一些技巧:
- 投机执行(Speculative Execution):总是假定不执行,预测错误则撤销执行的部分带来的影响。缺点是流水线越深,分支预测错误带来的惩罚越严重。
- 动态分支预测:分为局部动态分支预测和全局动态分支预测。局部是根据单条指令来判断,全局是根据所有指令的历史情况判断。
Lecture 5:从C语言到汇编
为什么要了解汇编语言?因为汇编语言可以展示编译器做的优化,而且某些bug来源于编译器(开了O3独有的),而且可以手动修改汇编,使得其运行更加快。下图是基于LLVM的编译器的编译流程:
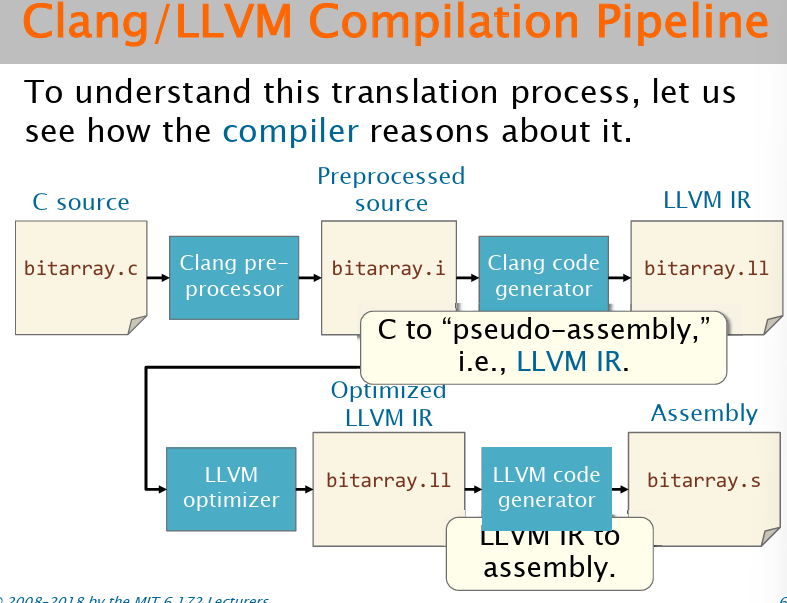
生成LLVM的中间表示,然后通过优化器生成优化后的IR,最后生成汇编代码。首先看看IR的中间表示长什么样(使用clang编译器,使用-emit-llvm可以产生中间表示。
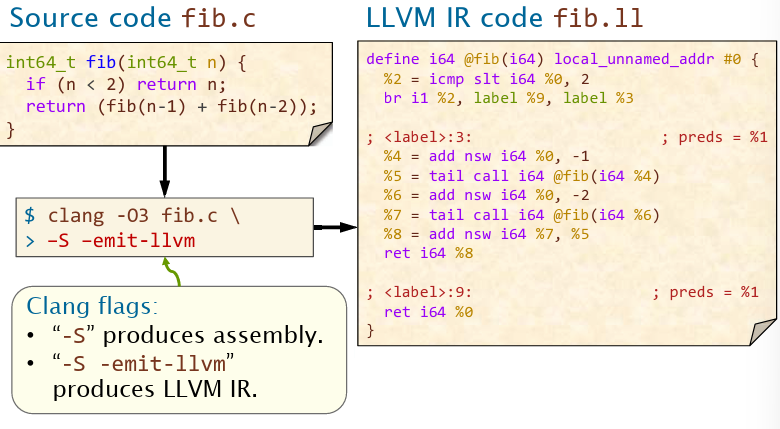
LLVM中间表示
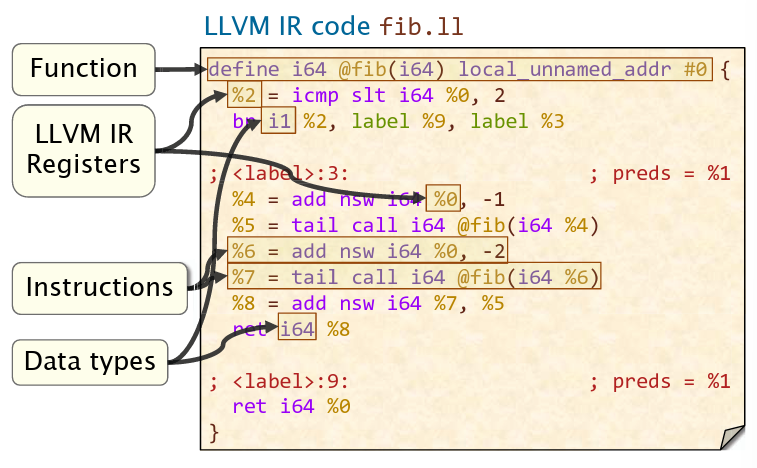
LLVM IR和汇编的区别:更小的指令集,寄存器是无限的,没有FLAG计数器和条件码,没有显式栈帧指针
- LLVM IR寄存器:用
%<name>表示,数量无限,相对于LLVM IR函数是局部的(即不同函数的寄存器编号可以相同) - LLVM IR指令:
- 产生结果的指令:
%<name> = <opcode> <operand list> - 其他指令:
<opcode> <operand list> - operand可以是寄存器,常数和基本块
- 指令列表如下:
- 产生结果的指令:
- LLVM IR数据类型
- 整数:
i<number>。例:3bit整数:i3 - 浮点数:float,double
- 数组:
[<number> x <type>] - 结构体:
{<type> ...} - 向量:
< <number> x <type> > - 指针:
<type>* - 标签
- 整数:
从C语言到LLVM IR
基本块转IR
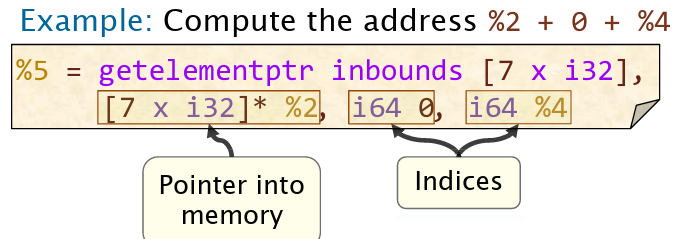
数组结构常保存在内存中。而LLVM IR中的getelementptr函数用于从指针和下标计算内存地址。
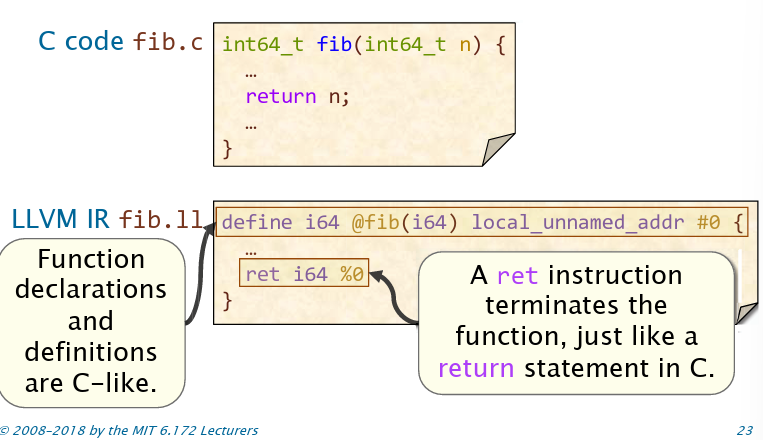
函数转IR
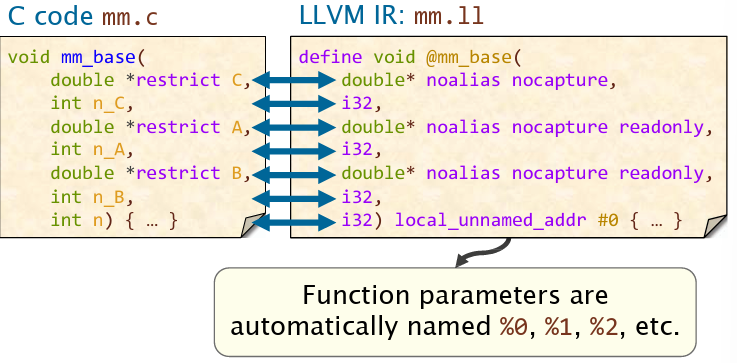
从C语言到LLVM IR的函数,形参列表一一对应。并且按顺序自动命名为%0, %1, %2...
基本块:一系列的指令,只有单个入口和单个出口。最后一条指令可以是跳转语句。
控制流图:基于跳转情况,可以建立CFG,其中每个节点是一个基本块。
条件语句转IR
条件跳转语句(if)会转成br <type> <reg>, label <reg>, label <reg>,其中第一个参数用于判断,为真则跳转到第一个label,否则为第二个label。比较语句会转成icmp指令。条件跳转语句总会创建菱形CFG。

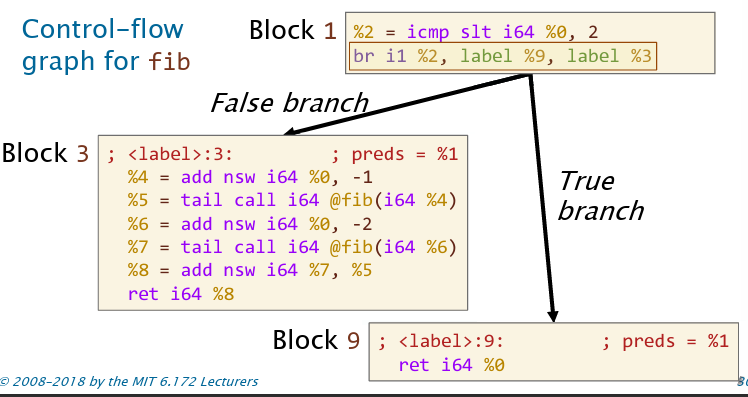
其中pred记录了前驱基本块。
无条件跳转语句则直接转换成br label <reg>,直接跳转。
循环转IR
循环包含循环体和循环控制两个部分。如下图所示。在CFG中会创建一个自循环部分。对于C语言的for循环,包含一个循环归纳变量(loop induction variable),包含初始化,条件和自增的部分。
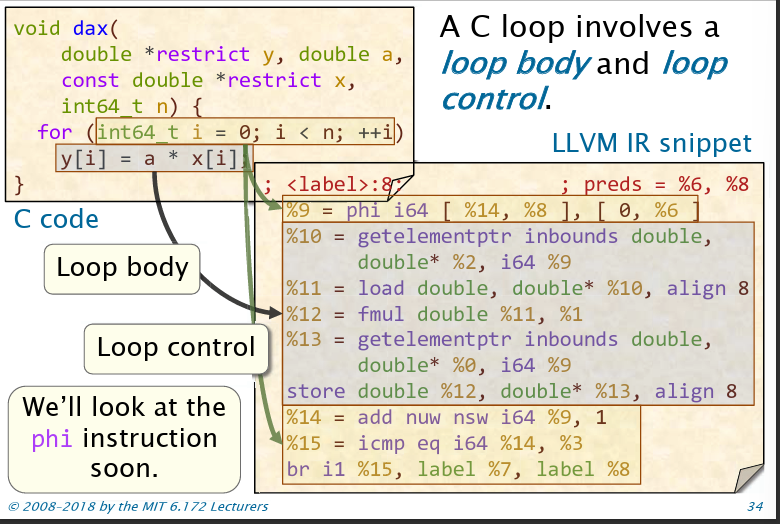
注意归纳变量自增的时候,寄存器会替换,原因是循环自增重定义了变量(需要满足SSA,下文提到)

LLVM IR维护静态单赋值(SSA, Static Single Assignment)的性质,即一个寄存器最多只能由一条指令赋值。这有利于进行数据流分析。但如果出现控制流的汇合,需要使用phi函数来维护这一性质:
1 | %9 = phi i64 [%14, %8], [ 0, %6 ] |
这个phi函数表示如果控制流从基本块8回来,则采用%14的值;从基本块6回来,则采用0。
IR属性
LLVM IR会为一些操作维护额外属性。这些属性的来源可能是源代码,也有可能是编译器分析。
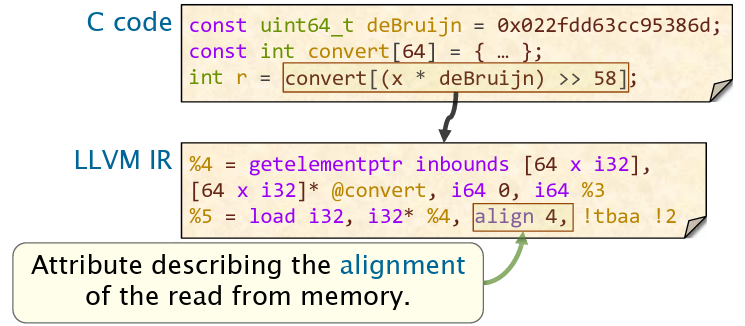

最后的总结:LLVM IR的特点是:所有计算出的值都会存入寄存器中,每个寄存器最多只有一条IR赋值,这个性质称为Static Single Assignment(SSA),同时IR会被建模为CFG,进行进一步的优化。
从LLVM IR到x86汇编
这一步需要考虑三个问题:
- 选择恰当的汇编指令
- 合理分配通用寄存器
- 处理函数调用
x86-64的函数调用约定
程序在虚拟空间中被划分为几个段,其中data段是初始化过的值,bss段是未初始化的值,默认初始化为0.
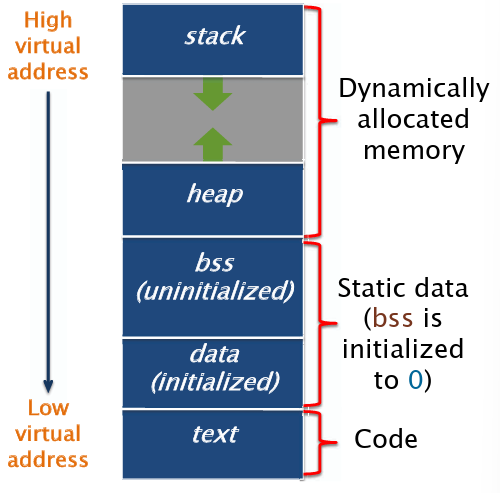
汇编代码包括两种指令:引用部分(section)的指令和操作部分(section)的指令。其中:
- 段指令将汇编代码文件组织为几个部分,包括
.bss,.data,.text等。 - 存储指令将相应的值存储在指定位置,如:
x: .space 20:在x处划分20字节的空位y: .long 172:在y处存储172Lz: .asciz "6.172":在z处存储"6.172\0".align 8:下面的内容按照八字节对齐。
- 域和链接指令:用于控制链接
.globl fib使符号fib对其他目标文件可见。
对于调用栈,有这些数据保存在栈上:返回地址,寄存器状态和函数参数,以及不能存入寄存器的局部参数。
x86-64的函数调用约定:
- 每个函数拥有自己的帧,其中
%rbp保存栈帧顶,%rsp保存栈帧底。 - 使用
call和ret实现调用栈和退栈,指令指针寄存器%rip用于处理返回地址。其中call将%rip压栈,ret则进行弹栈操作。 - 保存其他寄存器的内容:将寄存器分为
caller和callee,前者需要调用者保存,后者由被调用者保存。其中callee-saved registers为%rbx, %rbp, %r12-%r15,其他的均为调用者保存寄存器。而%xmm0-%xmm7通常用来传递浮点数参数。
原课程以Fibonacci为例再介绍了一下,略。愿意看的看原ppt即可。
Lecture 9 编译器能够做什么,不能做什么
首先看一下编译器的图景,可以发现LLVM相当于编译器中端,向下屏蔽了高级语言类型,向上屏蔽了平台架构。
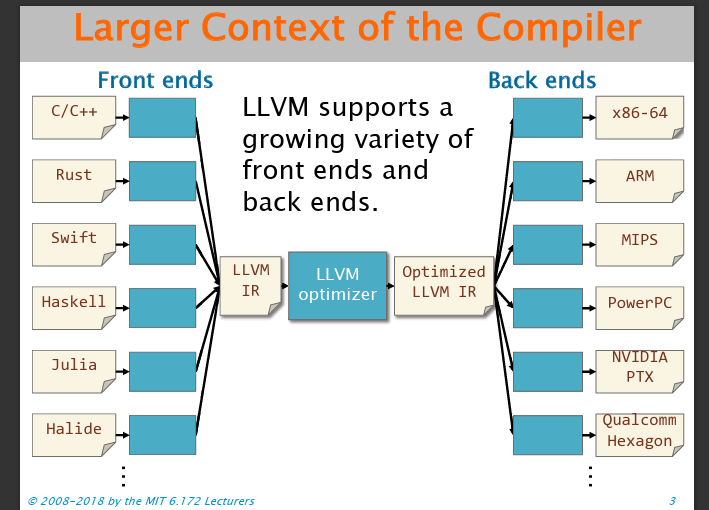
如何优化?编译器通过多遍变换,生成优化后的LLVM IR。下面是Clang/LLVM生成优化报告的参数:
-Rpass=<string>:生成关于指定优化方法的成功结果-Rpass-missed=<string>:失败结果-Rpass-analysis=<string>:前两者之和
例:clang -O3 test.c -Rpass=.* -Rpass-analysis=.*
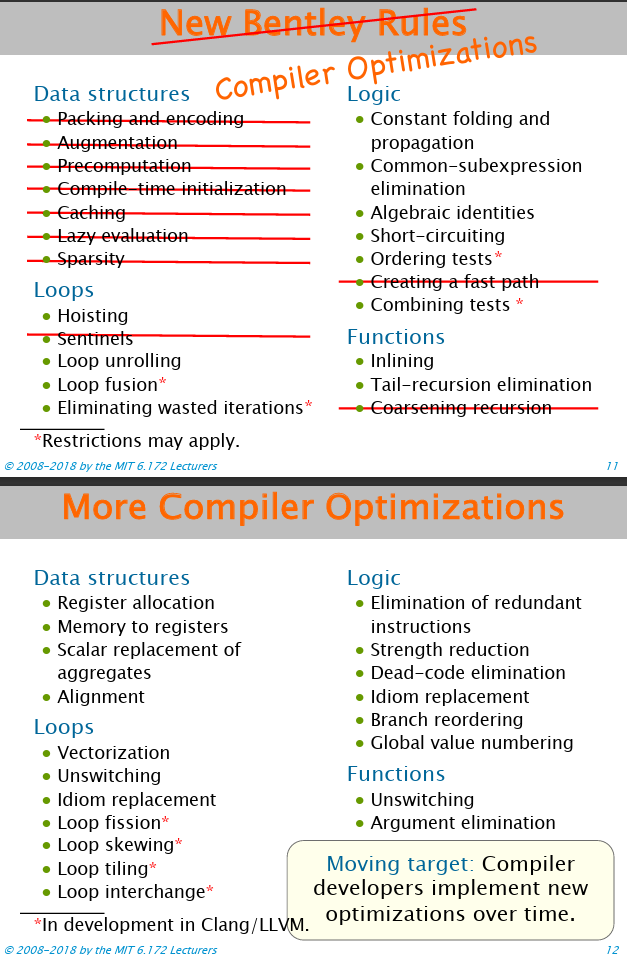
编译器优化
关于编译器能干的事罗列如下:
### 标量优化
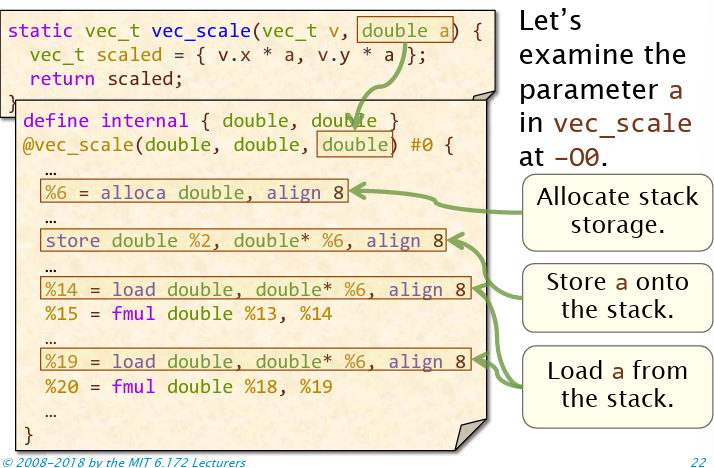
上面这幅图需要注意的点:LLVM IR函数参数,将struct展开了(vec_t是两个double组成的结构体),第一个优化点是略去内存读取操作,直接在寄存器进行操作。注意%15和%20,实际上%14和%19都可以换成%2,并消除死代码,获得优化效果。
结构体优化
结构体很难处理,因为往往操作的是结构体的其中某一个域。
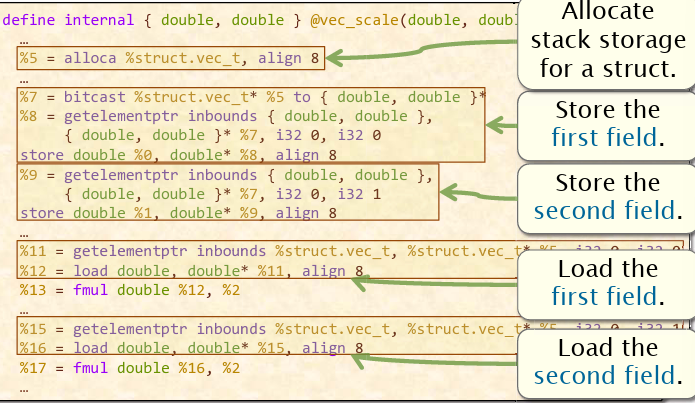
观察上面这一块代码,最后%13需要什么数?%12实际是什么?%0,前面对内存进行了相当多的存入存出操作,最后发现就是%0,那么,可以进行替换,并进行死代码消除。

总之,编译器尽量减少内存的读入读出操作,尽可能在寄存器内完成操作。
函数调用优化
①进行函数内联

但需要注意的是,不是所有函数都可以进行内联,如递归调用(除了尾递归调用可以优化),不能将定义在其他编译后的单元的函数进行内联(除非一起编译),同时,函数内联会导致代码大小增大。
编译器是否能判断函数是否内联呢?很遗憾的是并不知道,只能根据函数大小进行猜测。可以利用__attribute__((always_inline))对函数进行标记,令相应函数进行内联。使用__attribute__((no_inline))取消内联。同时,可以使用链接时优化(link-time optimization (LTO) )进行整体编译的优化。
循环优化
无关代码外提(code hoisting),或无关代码移动(loop-invariant code motion, LICM),目的在于将不依赖于循环归纳变量(loop induction variable)的语句提到循环外。
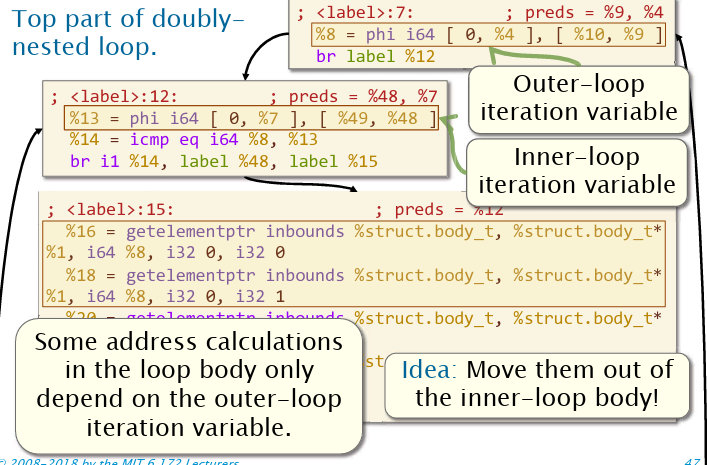
如图,里面两个框起来的语句只依赖于外层变量,因此可以考虑外提这些语句。对应的源代码如下。

但是编译器无法发掘什么问题呢?上个图的函数作用是计算力的大小,编译器是无法发现两个物体的相互作用力,大小相同,方向相反这个特点的。(背景是N体运动模拟问题)
失败的优化——样例学习
样例1 :向量的线性运算
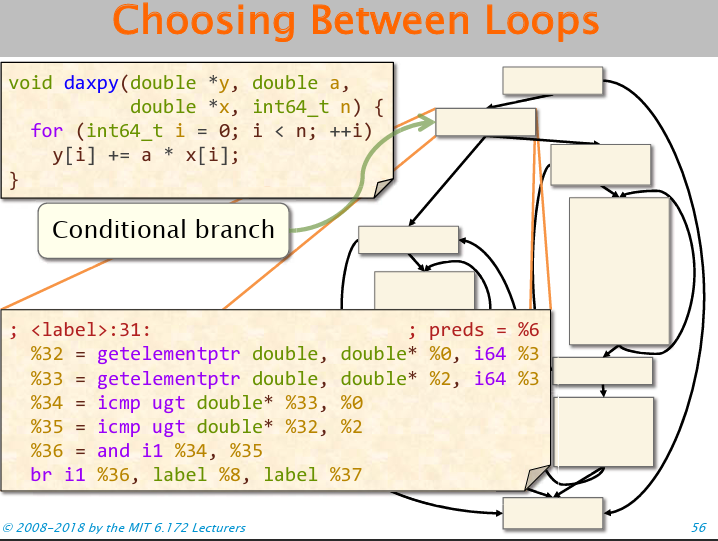
观察这段代码,这个分支是什么呢?其实是判断两个数组是不是一个东西,然后根据结果跑不同的指令。可以看到,编译器产生了两个版本的指令,因为存在内存别名(memory aliasing)的问题!可以使用restrict关键字修饰入参,表明这两个地址一定不是同一个地址,从而消除内存别名的问题。同时,const修饰符表明只读的属性。
样例2:归一化
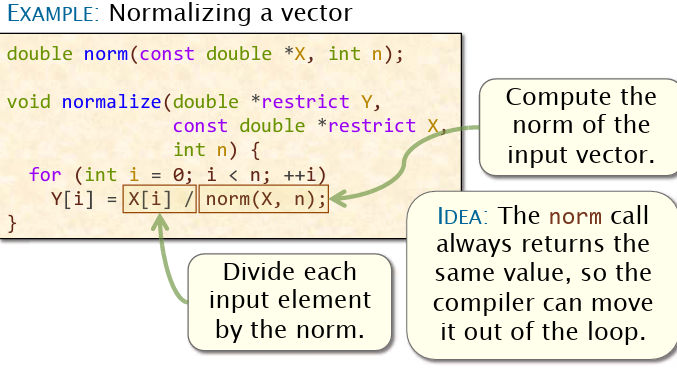
将每次计算都能得到相同结果的,但计算代价大的成分扔出循环。但编译器为什么没有优化?因为编译器不知道传入的参数,内容是否会被修改!因此,在norm函数声明的最前面可以加上__attribute__((const))来声明不会有修改,从而达到优化目的。
样例3:显式循环展开

如图,由于循环次数不确定,无法进行向量化。为什么?因为传入参数是size_t,这是个无符号整数!注意由于无符号整数的溢出是个Undefined Behavior,编译器的行为不确定(可能优化可能没有优化)。修改方法是改用有符号整数。
链接时优化
主要是单个编译单元优化程度不够,可以进行链接时优化,clang编译器开启-flto将源代码编译成LLVM IR形式,带上-fuse-ld=gold将LLVM IR代码链接在一起。
总结
本篇文章对第1节课到第5节课,以及第9节课的内容进行了总结,其中:
- 第1节课
- 以矩阵乘法为例,介绍了一系列优化的效果
- 第2节课
- 介绍了一些优化技巧,并且这些技巧大多数可以被编译器识别,但仍然需要了解
- 第3节课
- 关于位操作的一些骚操作
- 第4节课
- 介绍了x86 ISA,其中需要掌握的内容有:
- 所拥有的寄存器,作用,以及寄存
- 器别名的设计,寄存器的前缀,后缀的含义
- 常见指令,以及常见指令的后缀
- x86的条件RFLAGS寄存器的相关设计(ZF,OF...)
- x86的寻址模式
- 向量指令集 SSE,AVX,AVX2和AVX3的特点
- 指令集的前缀(
[v ][p ])后缀([sp][sd])
- 之后介绍了计算机体系结构相关的内容,主要是从五级流水线到现代处理器流水线特征的过渡,包括:
- 向量体系结构
- 超标量处理
- 乱序执行:数据冒险的处理,以及针对WAR和WAW的寄存器重命名技术
- 分支预测:投机执行和动态分支预测
- 介绍了x86 ISA,其中需要掌握的内容有:
- 第5节课
- 对LLVM IR进行了初步介绍,需要知道
- 基本块的定义
- SSA,phi函数
- CFG
- 进程的虚拟地址空间组织方式,有哪些段以及作用(.text,.bss,.data...)
- 汇编代码文件的组织,汇编代码的一些特殊指令
- x86-64的函数调用约定
- 对LLVM IR进行了初步介绍,需要知道
- 第9节课
- 了解编译器的优化问题,包括
- 编译器输出优化报告
- 通过减少访存次数,尽量在寄存器中进行操作,同时消除死代码
- 函数内联,哪些函数不能函数内联,以及优缺点
- 影响编译器优化的因素,包括:
- 寄存器别名问题,C语言的关键字
restrict - 不确定的内存修改:对相关函数加上
__attribute__((const))修饰符,表明相应函数不会对传入参数的内容进行修改。 - undefined behavior行为导致优化的不确定性:如无符号整数导致的溢出。
- 寄存器别名问题,C语言的关键字
- 链接时优化
- 了解编译器的优化问题,包括
- Title: 【MIT6.172】学习笔记(1)
- Author: spiritTrance
- Created at : 2024-02-09 13:48:00
- Updated at : 2025-01-29 17:02:09
- Link: https://spirittrance.github.io/2024/02/09/MIT6.172_ch1/
- License: This work is licensed under CC BY-NC-SA 4.0.

