
【MIT6.172】学习笔记(2)

前言
从这篇博客开始,就开始进入多线程程序的优化部分了。同样地,有错误请直接指出,十分感谢!
Lecture 6 多核编程
多核出现的动机:频率无法进一步提高,大概在4GHz左右(功耗墙),摩尔定律。
缓存一致性
需要解决的问题:由于独立缓存的存在,多核对于相同物理地址所取得的数据要相同。因此有了MSI协议。这方面的详细介绍请见《计算机体系结构:量化研究方法》的第五章,此处不再详细介绍。
并发平台
首先把糟糕的代码放在这里,以便于提供良好示例。

pthreads
这是ANSI/IEEE POSIX 1003.1-2008指定的标准API。线程通过共享内存进行通信。(进程间通信还有哪些方法?信号量,管道,套接字,消息队列,RPC...)

pthreads有两个很重要的函数pthread_create和pthread_join,这里给出编程模板,具体用法请查文档:
1 | typedef struct{ |
需要关注的问题是,线程创建的开销很大,大约在\(10^4\)cycles的数量级。可以考虑线程池的帮助。
Threading Building Blocks(线程构建块,TBB)
其由intel发明,作为本地线程之上的cpp库实现。程序员声明的是任务(tasks)而不是线程(threads)。使用work-stealing算法实现线程间的负载平衡。

上图主要关注的是红色标出的函数。以及任务单位是task,需要用class提前定义并继承过来,需要声明构造函数和execute()方法。需要注意其中创建子任务的方法。
需要注意set_ref_count的方法,其中参数是需要等待的任务个数(两个子任务,一个隐式声明的记账(bookkeeping)任务。spawb(b)表示启动任务b,spawn_and_wait_for_all(a)表示启动a并等待a和b任务的结束。
最后的spawn_root_and_wait(a)的作用是启动根任务。
需要知道的是,TBB提供了大量的cpp模板用于执行基本的操作,如:parallel_for用于循环并行化,parallel_reduce用于归约操作,pipeline和filter用于软件流水线。除此之外,还提供了concurrent container类,允许多线程并发安全地访问和更新容器内的内容。TBB还提供了mutual-exclusion库函数,包括锁和原子更新操作。
openmp
行业协会的规范,几个编译器是提供的,如gcc,icc,clang和msvc。在本机线程上运行,提供循环并行,任务并行和管道并行。

看得出来真的很简单,但是也很常用。后面另外开一个博客介绍openmp。
cilk
是对cpp的语法扩展。提供了监测竞争机制的工具cilkscreen和扩展性分析器cilkview。
Fibonacci示例:
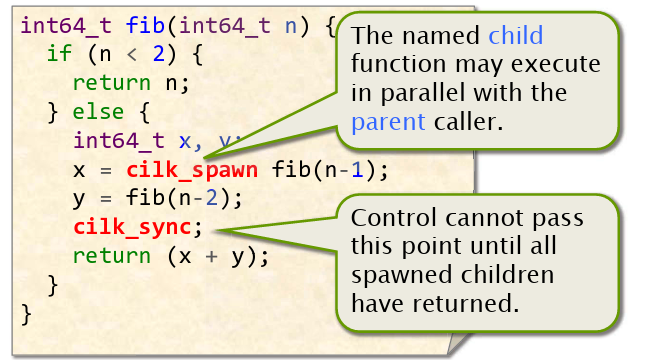
并行化循环示例:

归约运算实例:

Lecture 7 竞争和并行
确定性竞争
确定性竞争:两个指令访问相同的物理内存位置,并且至少存在一个写操作,那么就是确定性竞争。竞争类型包括读竞争(一读一写)和写竞争(同时写).如果使用的是cilk,可以使用cilksan工具检查是否有竞争出现。
对于一个并行正序,可以建立computational DAG:
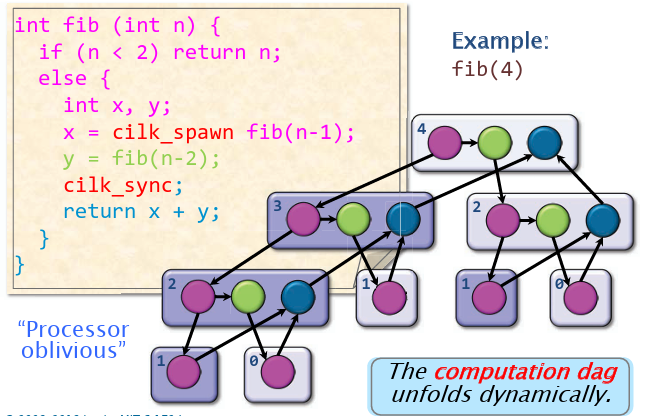
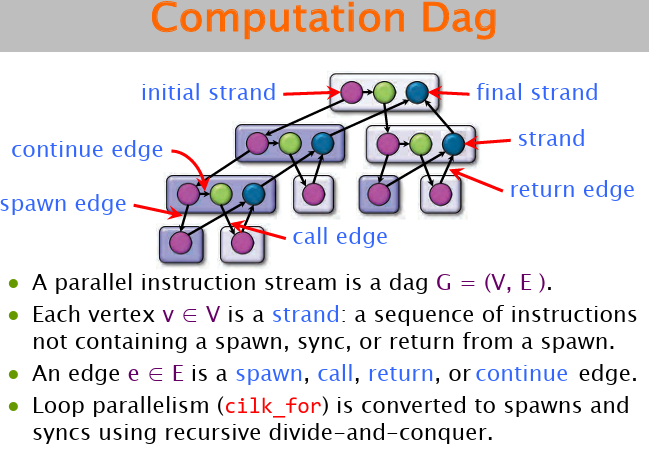
阿姆达尔定律:如果一个应用有p(0<p<1)的部分必须串行执行,那么最大的加速比为1/p。
如何根据计算图获取加速比呢?找计算图的关键路径即可。
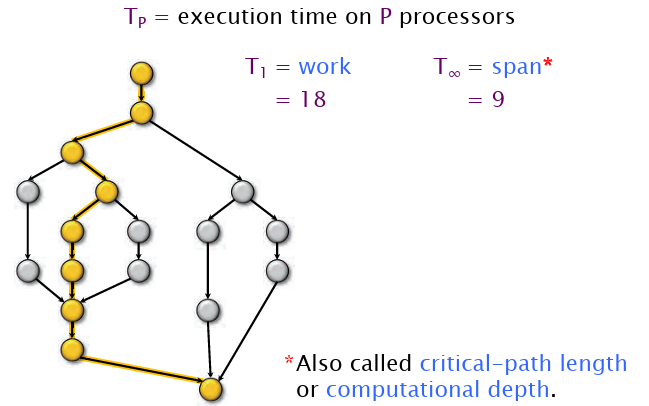
图中一个节点代表一个工作负载。
令\(T_p\)表示程序在\(p\)个处理器上的工作时间,那么根据\(T_1\)和\(T_p\)的比值,有sublinear speedup(不知道怎么翻译好),线性加速比和超线性加速比的概念。加速比是两个时间之比。
可扩展性分析
Tapir/LLVM编译器,提供可扩展性分析器Cilkscale。

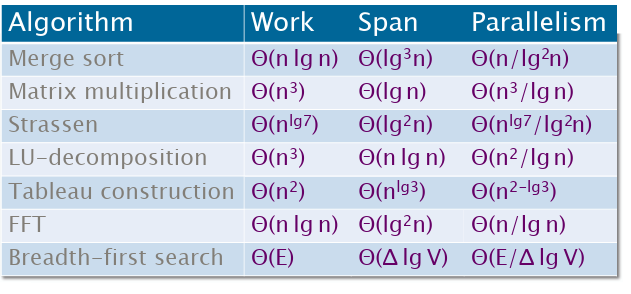
快速排序的时间复杂度为\(O(nlgn)\),那么理论上的并行性为\(O(lgn)\)(无限个处理器后的时间复杂度为\(O(n)\))(问题:在理论上如何分析?)
下面是其他算法的并行时间复杂度。其中work是单核时间复杂度,span是无限多核心下的时间复杂度(怎么分析出来的?),并行性为work/span。
调度理论
本章主要探讨集中式调度器,不讨论分布式调度器。调度器负责将计算图的节点分配到处理器上。
贪心调度算法:只要一个节点的前驱节点都处理好了,就开始分配处理。尽量在每一步都尽可能分配最多。
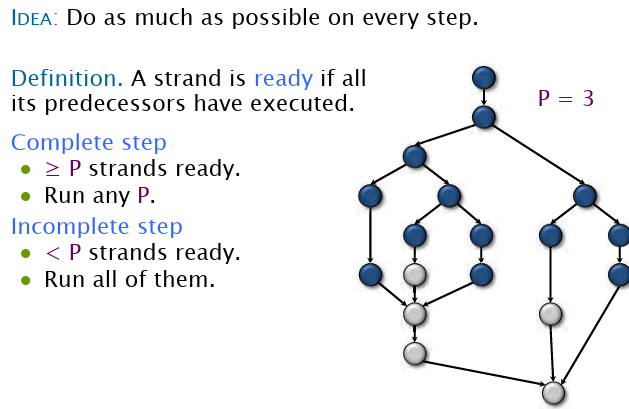
完全步骤和不完全步骤无非就是描述处理器利用充不充分了。
定理:基于贪心调度算法的耗时上限满足:
\(T_p\leq T_1/P+T_{\infin}\)
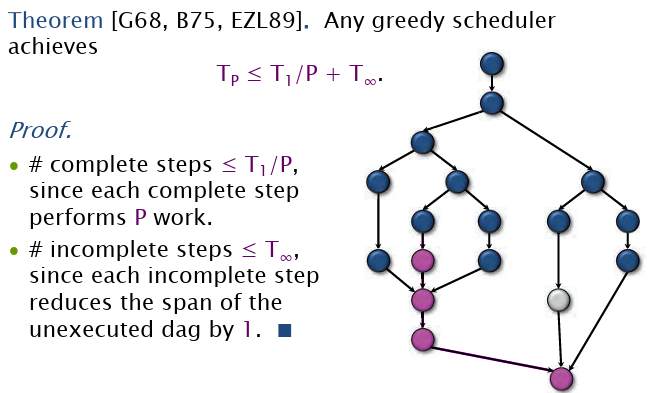
推论1:任何贪心调度器调度的结果所使用的时间最多在最优时间的二倍内实现。

推论2:任何贪心调度器最多能实现近线性比加速,当算法满足\(T_1/T_{\infin}>>P\)的时候。其中\(T_1/(PT_{\infin})\)被称为并行松弛度(parallel slackness).

cilk运行时系统
cilk的work-stealing调度器能满足以下特征:

每个处理器维护一个工作队列。这个工作队列表现得像双端队列。每个处理器每产生一次任务,就往自己的工作队列的底部压入相应的工作(spawn/call),执行完,return的时候,就从自己的工作队列底部弹出相应工作。当一个处理器工作队列为空的时候,就会随机“窃取”其他不为空的工作队列的顶部的工作到自己的工作队列中。
定理:充分的并行性使得“偷窃”很少发生,从而能够获得近线性加速比。换句话说,一个问题规模的可扩展性是看算法并行性写的好不好,如果写的不好,“偷窃”动作经常发生,带来开销,就难以达到线性加速比,从而导致问题不具备可扩展性。

仙人掌堆栈数据结构的特点:维护一颗树,子节点视角下的栈,可以看到其祖先,一直到根节点。
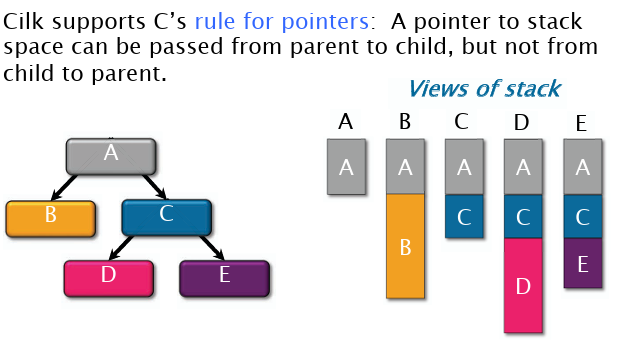
定理:规定串行算法所需的栈空间为\(S_1\),P个处理器所需空间为\(S_P\),则满足:\(S_P\leq PS_1\).
Lecture 8 多线程程序算法分析
分治递归
主定理(Master Method):
> 对于满足\(T(n)=aT(n/b)+f(n)\)的分治问题,满足\(a\geq 1, b\geq 1\):满足:
> 
> 证明略。推荐看ppt,有图,有意思。也可以看《算法导论》。
> 更一般的结论是Akra-Bazzi Method,有兴趣可以了解,更复杂。
cilk循环(矩阵转置),矩阵乘法,归并排序,打印数表
这一段强烈建议看原ppt,我在这里相当于把ppt誊了一遍,所以略。主要讲了算法的实现,并行算法的时间复杂度和并行度的分析。都是举的例子看的。这里还是罗列一下需要掌握的内容:
- cilk_for的内部实现也是类似于二分的写法,使用cilk_spawn和cilk_sync实现的,这样展开的时间就是\(O(lgn)\)。
- 需要考虑分解问题的粒度,到了什么程度就开始不再分解,但分解程度需要小心考虑,最好建立理论模型再分析。
- 分析一般分析两个时间复杂度:Work和Span,前者为单个处理器所花费时间,后者为无限个处理器,所花费的时间(也就是单个处理器所分配的任务所花时间),两者相除就是并行度。
- 矩阵乘法的时间复杂度分析很有意思,还是截图下来看看:
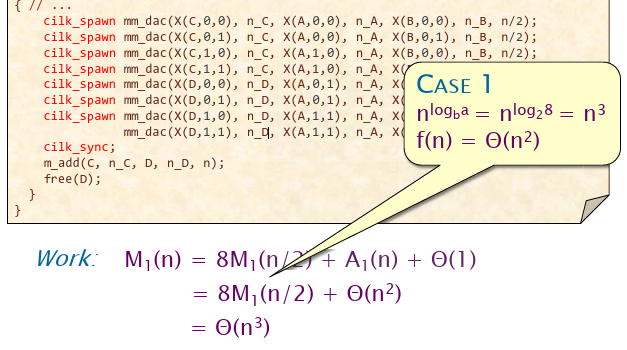

并且矩阵乘法考虑了主定理,有动态申请空间和不动态申请空间的问题。下面是时间复杂度分析
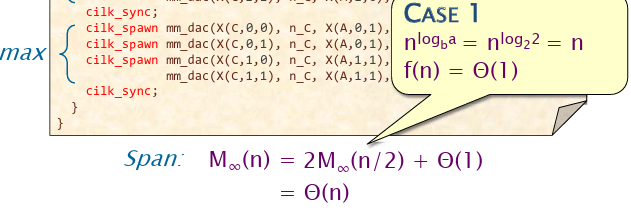
- 在归并排序中,探究了序列划分的不平衡问题对时间复杂度带来的影响。属于算法分析的范畴了。
Lecture 10 测量和计时
静默系统
尽量减少系统的可变性,从而提高测量的精确度。下面这些是可变性的来源:

在测量时,需要注意:
- 没有其他任务运行
- 关闭守护进程和定时任务
- 不要连接网络
- 不要摆弄鼠标!!!!!!!!!!!(引发中断!)
- 串行任务不要使用0号cpu(因为0号cpu经常执行中断任务)
- 关闭超线程
- 关闭DVFS
- 不要超频(Turbo boost)
- 使用taskset将工作负责固定在某个核心中
关于内存对齐:链接顺序的不同会导致机器码最终的不同,进而导致对齐状况不一样,可能会影响性能。LLVM编译器提供了一一些选项控制代码对齐:-align-all-functions=<uint>,-align-all-blocks=<uint>,-align-all-nofallthru-blocks=<uint>。值得一提的是,由于文件名最终也会出现在目标文件中,因此文件名也会影响数据对齐问题,进而影响性能。
测量软件性能的工具
有下列工具可以使用:
- 外部测量:/usr/bin/times
- real是墙钟时间,user和sys分别是用户所用时间和内核所用时间。
- 程序源码修改:clock_gettime()
- 注意rdtsc()有很多问题,不要用这个测量时间
- 中断程序:gdb,pmprof,gprof等
- 硬件和OS的支持:perf
- 程序模拟:cachegrind
- 比实时运行慢,但是可重复
性能建模
如果计算机有一些烦人的噪声,那么使用什么可以代表程序的性能呢?答案是最小值(而不是平均值或者其他)。
下图是在不同场景下使用的不同性能度量:

计算性能加速的平均值需要使用几何平均值(原因:使用算数平均值导致A/B和B/A是不可逆的)

Lecture 13 Cilk运行时系统
略,有需要再学。
Lecture 20 推测并行
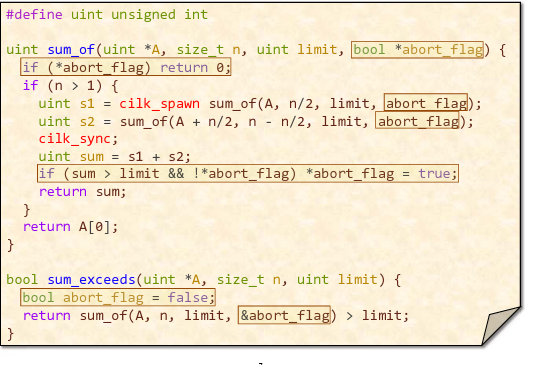
这段代码中,abort_flag可能会出现争用(WAW),但由于只可能从false变成true(不可能有其他结果),因此这里的争用是没有太大问题的。
推测并行(Speculative parallelism)是指在并行程序中可能出现,但在串行程序中不会出现的行为。尽量不要出现这种行为,除非有在并行场合下有优化的机会。
总结
- 第6节课:多核编程
- 了解缓存一致性的问题,MSI协议
- 了解场景的多线程框架:
- pthreads
- TBB
- openmp
- cilk
- 第7节课:竞争和并行
- 确定性竞争的定义及种类
- 扩展性问题
- 并行程序的建模:计算图
- 调度方案:贪心算法;work-stealing算法
- 仙人掌堆栈数据结构
- 第8节课:多线程程序算法分析
- 主定理
- 并行算法的时间复杂度,并行度分析(举了四个例子,更推荐找原ppt看)
- 了解cilk_for的时间复杂度,并明白对并行算法所带来的时间复杂度分析的影响
- 第10节课:测量和计时
- 了解影响测量结果的场外因素
- 了解测量常用的工具
- 了解在不同场合下应该选择什么指标衡量程序性能
- 了解测量加速比的平均值使用几何平均值及其原因
- 第13节课:cilk运行时系统
- 略,没学
- 第20节课:推测并行
- 了解推测并行的概念,存在竞争问题的代码什么时候才可以写出来。
- Title: 【MIT6.172】学习笔记(2)
- Author: spiritTrance
- Created at : 2024-02-09 13:48:00
- Updated at : 2025-01-29 10:43:44
- Link: https://spirittrance.github.io/2024/02/09/MIT6.172_ch2/
- License: This work is licensed under CC BY-NC-SA 4.0.

